Обзор основных функций Google BigQuery и примеры запросов для маркетинг-анализа
Google BigQuery – это быстрое, экономичное и масштабируемое хранилище для работы с Big Data, которое вы можете использовать, если у вас нет возможности или желания содержать собственные серверы. В нем можно писать запросы с помощью SQL-like синтаксиса, стандартных и пользовательских функций (User-defined function).
Что такое SQL и какие у него диалекты
SQL (Structured Query Language) — язык структурированных запросов для работы с базами данных. С его помощью можно получать, добавлять в базу и изменять большие массивы данных. Google BigQuery поддерживает два диалекта: Standard SQL и устаревший Legacy SQL.
Какой диалект выбрать, зависит от ваших предпочтений, но Google рекомендует использовать Standard SQL из-за ряда преимуществ:
- Гибкость и функциональность при работе с вложенными и повторяющимися полями.
- Поддержка языков DML и DDL, которые позволяют менять данные в таблицах, а также управлять таблицами и представлениями в GBQ.
- Скорость обработки больших объемов данных выше, чем у Legasy SQL.
- Поддержка всех текущих и будущих обновлений в BigQuery.
Подробнее о разнице между диалектами вы можете узнать в справке.
По умолчанию запросы в Google BigQuery запускаются на Legacy SQL.
Переключиться на Standard SQL можно несколькими способами:
-
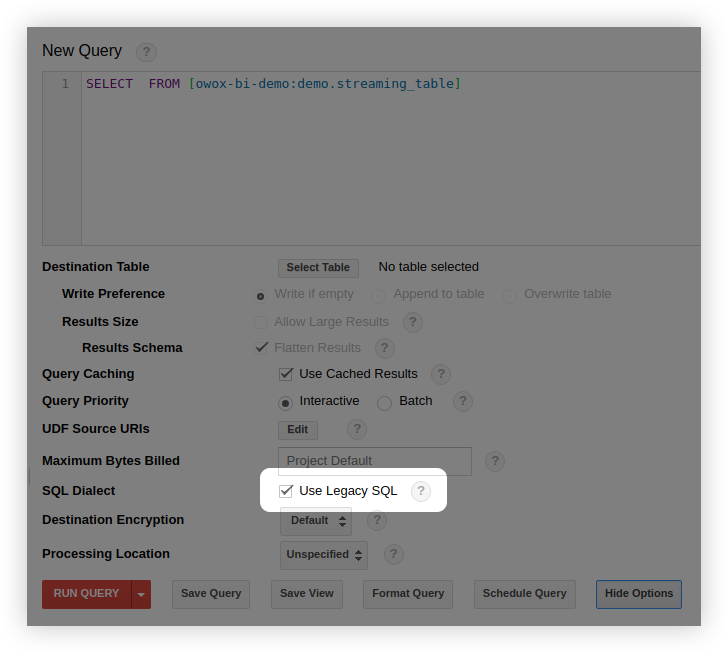
В интерфейсе BigQuery в окне редактирования запроса выберите «Show Options» и снимите галочку возле опции «Use Legacy SQL»
-
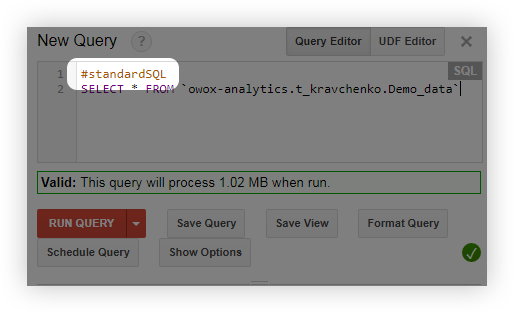
Перед запросом добавьте строку #standardSQL и начните запрос с новой строки
С чего начать
Чтобы вы смогли потренироваться запускать запросы параллельно с чтением статьи, я подготовила для вас таблицу с demo-данными. Загрузите данные из таблицы в ваш проект Google BigQuery.
Если у вас еще нет проекта в GBQ, создайте его. Для этого понадобится активный биллинг-аккаунт в Google Cloud Platform. Понадобится привязать карту, но без вашего ведома деньги с нее списываться не будут, к тому же при регистрации вы получите 300$ на 12 месяцев, который сможете потратить на хранение и обработку данных.
Функции Google BigQuery
При построении запросов чаще всего используются следующие группы функций: Aggregate function, Date function, String function и Window function. Теперь подробнее о каждой из них.
Функции агрегирования данных (Aggregate function)
Функции агрегирования позволяют получить сводные значения по всей таблице. Например, рассчитать средний чек, суммарный доход за месяц или выделить сегмент пользователей, совершивших максимальное количество покупок.
Вот самые популярные функции из этого раздела:
|
Legacy SQL |
Standard SQL |
Что делает функция |
|
AVG(field) |
AVG([DISTINCT] (field)) |
Возвращает среднее значение столбца field.В Standard SQL при добавлении условия DISTINCT среднее считается только для строк с уникальными (не повторяющимися) значениями из столбца field |
|
MAX(field) |
MAX(field) |
Возвращает максимальное значение из столбца field |
|
MIN(field) |
MIN(field) |
Возвращает минимальное значение из столбца field |
|
SUM(field) |
SUM(field) |
Возвращает сумму значений из столбца field |
|
COUNT(field) |
COUNT(field) |
Возвращает количество строк в столбце field |
|
EXACT_COUNT_DISTINCT(field) |
COUNT([DISTINCT] (field)) |
Возвращает количество уникальных строк в столбце field |
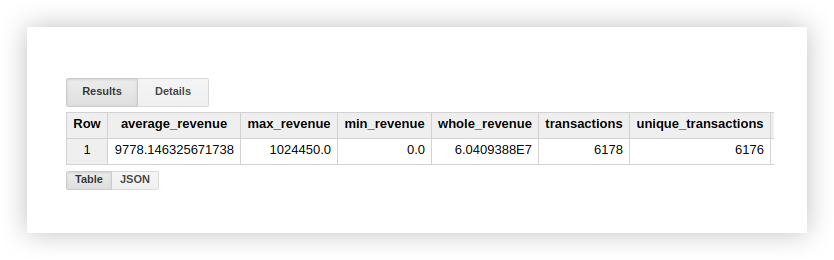
С перечнем всех функций вы можете ознакомиться в справке: Legacy SQL и Standard SQL. Давайте посмотрим на примере demo данных, как работают перечисленные функции. Вычислим средний доход по транзакциям, покупки с наибольшей и наименьшей суммой, общий доход и количество всех транзакций. Чтобы проверить, не дублируются ли покупки, рассчитаем также количество уникальных транзакций. Для этого пишем запрос, в котором указываем название своего Google BigQuery проекта, набора данных и таблицы.
#legasy SQL SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data] #standard SQL SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`
В итоге получаем такие результаты:
Проверить результаты расчетов вы можете в исходной таблице с demo данными, используя стандартные функции Google Sheets (SUM, AVG и другие) или сводные таблицы.
Как видим из скриншота выше, количество транзакций и уникальных транзакций отличается.
Это говорит о том, что в нашей таблице есть 2 транзакции, у которых дублируется transactionId:

Поэтому, если вас интересуют именно уникальные транзакции, используйте функцию, которая считает уникальные строки. Либо вы можете сгруппировать данные с помощью выражения GROUP BY, чтобы избавиться от дублей перед тем, как применять функцию агрегации.
Функции для работы с датами (Date function)
Эти функции позволяют обрабатывать даты: менять их формат, выбирать необходимую часть (день, месяц или год), смещать дату на определенный интервал.
Они могут вам пригодится в следующих случаях:
- При настройке сквозной аналитики — чтобы привести даты и время из разных источников к единому формату.
- При создании автоматически обновляемых отчетов или триггерных рассылок. Например, когда нужны данные за последние 2 часа, неделю или месяц.
- При создании когортных отчетов, в которых необходимо получить данные в разрезе дней, недель, месяцев.
Функции для работы с датами, используемые чаще всего:
|
Legacy SQL |
Standard SQL |
Что делает функция |
|
CURRENT_DATE() |
CURRENT_DATE() |
Возвращает текущую дату в формате %ГГГГ-%ММ-%ДД |
|
DATE(timestamp) |
DATE(timestamp) |
Преобразует дату из формата %ГГГГ-%ММ-%ДД %Ч:%M:%С. в формат %ГГГГ-%ММ-%ДД |
|
DATE_ADD(timestamp, interval, interval_units) |
DATE_ADD(timestamp, INTERVAL interval interval_units) |
Возвращает дату timestamp, увеличивая ее на указанный интервал interval.interval_units. В Legacy SQL может принимать значения YEAR, MONTH, DAY, HOUR, MINUTE и SECOND, а в Standard SQL — YEAR, QUARTER, MONTH, WEEK, DAY |
|
DATE_ADD(timestamp, — interval, interval_units) |
DATE_SUB(timestamp, INTERVAL interval interval_units) |
Возвращает дату timestamp, уменьшая ее на указанный интервал interval |
|
DATEDIFF(timestamp1, timestamp2) |
DATE_DIFF(timestamp1, timestamp2, date_part) |
Возвращает разницу между двумя датами timestamp1 и timestamp2. |
|
DAY(timestamp) |
EXTRACT(DAY FROM timestamp) |
Возвращает день из даты timestamp. Принимает значения от 1 до 31 включительно |
|
MONTH(timestamp) |
EXTRACT(MONTH FROM timestamp) |
Возвращает порядковый номер месяца из даты timestamp. Принимает значения от 1 до 12 включительно |
|
YEAR(timestamp) |
EXTRACT(YEAR FROM timestamp) |
Возвращает год из даты timestamp |
Список всех функций – в справке: Legacy SQL и Standard SQL. Рассмотрим на demo данных, как работает каждая из приведенных функций. К примеру, получим текущую дату, приведем дату из исходной таблицы в формат %ГГГГ-%ММ-%ДД, отнимем и прибавим к ней по одному дню. Затем рассчитаем разницу между текущей датой и датой из исходной таблицы и разобьем текущую дату отдельно на год, месяц и день. Для этого вы можете скопировать примеры запросов ниже и заменить в них название проекта, набора данных и таблицы с данными на свои.
#legasy SQL
SELECT
CURRENT_DATE() AS today,
DATE( date_UTC ) AS date_UTC_in_YYYYMMDD,
DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day,
DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day,
DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date,
DAY( CURRENT_DATE() ) AS the_day,
MONTH( CURRENT_DATE()) AS the_month,
YEAR( CURRENT_DATE()) AS the_year
FROM
[owox-analytics:t_kravchenko.Demo_data]
#standard SQL
SELECT
today,
date_UTC_in_YYYYMMDD,
DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day,
DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day,
DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date,
EXTRACT(DAY FROM today ) AS the_day,
EXTRACT(MONTH FROM today ) AS the_month,
EXTRACT(YEAR FROM today ) AS the_year
FROM (
SELECT
CURRENT_DATE() AS today,
DATE( date_UTC ) AS date_UTC_in_YYYYMMDD
FROM
`owox-analytics.t_kravchenko.Demo_data`)После применения запроса вы получите вот такой отчет:

Функции для работы со строками (String function)
Строковые функции позволяют формировать строку, выделять и заменять подстроки, рассчитывать длину строки и порядковый номер индекса подстроки в исходной строке.
Например, с их помощью можно:
- Сделать в отчете фильтры по UTM-меткам, которые передаются в URL страницы.
- Привести данные к единому формату, если название источников и кампании написаны в разных регистрах.
- Заменить некорректные данные в отчете, например, если название кампании передалось с опечаткой.
Самые популярные функции для работы со строками:
|
Legacy SQL |
Standard SQL |
Что делает функция |
|
CONCAT('str1', 'str2') или'str1'+ 'str2' |
CONCAT('str1', 'str2') |
Объединяет несколько строк 'str1' и 'str2' в одну |
|
'str1' CONTAINS 'str2' |
REGEXP_CONTAINS('str1', 'str2') или 'str1' LIKE ‘%str2%’ |
Возвращает true если строка 'str1' содержит строку ‘str2’. |
|
LENGTH('str' ) |
CHAR_LENGTH('str' ) |
Возвращает длину строки 'str' (количество символов в строке) |
|
SUBSTR('str', index [, max_len]) |
SUBSTR('str', index [, max_len]) |
Возвращает подстроку длиной max_len, начиная с символа с индексом index из строки 'str' |
|
LOWER('str') |
LOWER('str') |
Приводит все символы строки 'str' к нижнему регистру |
|
UPPER(str) |
UPPER(str) |
Приводит все символы строки 'str' к верхнему регистру |
|
INSTR('str1', 'str2') |
STRPOS('str1', 'str2') |
Возвращает индекс первого вхождения строки 'str2' в строку 'str1', иначе — 0 |
|
REPLACE('str1', 'str2', 'str3') |
REPLACE('str1', 'str2', 'str3') |
Заменяет в строке 'str1' подстроку 'str2' на подстроку 'str3' |
Детальнее – в справке: Legacy SQL и Standard SQL.
Разберем на примере demo данных, как использовать описанные функции. Предположим, у нас есть 3 отдельных столбца, которые содержат значения дня, месяца и года:
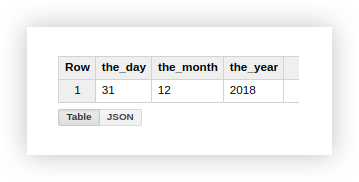
Работать с датой в таком формате не очень удобно, поэтому объединим ее в один столбец. Чтобы сделать это, используйте SQL-запросы, приведенные ниже, и не забудьте подставить в них название своего проекта, набора данных и таблицы в Google BigQuery.
#legasy SQL
SELECT
CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1,
the_day+'-'+the_month+'-'+the_year AS mix_string2
FROM (
SELECT
'31' AS the_day,
'12' AS the_month,
'2018' AS the_year
FROM
[owox-analytics:t_kravchenko.Demo_data])
GROUP BY
mix_string1,
mix_string2
#standard SQL
SELECT
CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1
FROM (
SELECT
'31' AS the_day,
'12' AS the_month,
'2018' AS the_year
FROM
`owox-analytics.t_kravchenko.Demo_data`)
GROUP BY
mix_string1
После выполнения запроса мы получим дату в одном столбце:
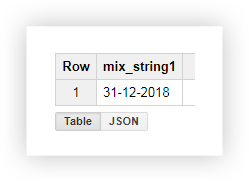
Часто при загрузке определенной страницы на сайте в URL записываются значения переменных, которые выбрал пользователь. Это может быть способ оплаты или доставки, номер транзакции, индекс физического магазина, в котором покупатель хочет забрать товар и т. д. С помощью SQL-запроса можно выделить эти параметры из адреса страницы. Рассмотрим два примера, как и зачем это делать. Пример 1. Предположим, мы хотим узнать количество покупок, при которых пользователи забирают товар из физических магазинов. Для этого нужно посчитать количество транзакций, отправленных со страниц, в URL которых есть подстрока shop_id (индекс физического магазина). Делаем это с помощью следующих запросов:
#legasy SQL
SELECT
COUNT(transactionId) AS transactions,
check
FROM (
SELECT
transactionId,
page CONTAINS 'shop_id' AS check
FROM
[owox-analytics:t_kravchenko.Demo_data])
GROUP BY
check
#standard SQL
SELECT
COUNT(transactionId) AS transactions,
check1,
check2
FROM (
SELECT
transactionId,
REGEXP_CONTAINS( page, 'shop_id') AS check1,
page LIKE '%shop_id%' AS check2
FROM
`owox-analytics.t_kravchenko.Demo_data`)
GROUP BY
check1,
check2
Из полученной в результате таблицы мы видим, что со страниц, содержащих shop_id, отправлено 5502 транзакции (check = true):
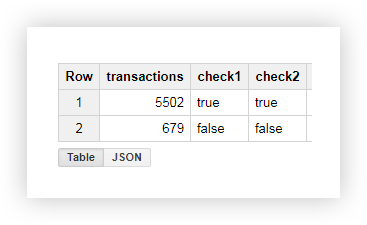
Пример 2. Допустим, вы присвоили каждому способу доставки свой delivery_id и прописываете значение этого параметра в URL страницы. Чтобы узнать, какой способ доставки выбрал пользователь, нужно выделить delivery_id в отдельный столбец. Используем для этого следующие запросы:
#legasy SQL
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
selected_delivery_id,
REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id
FROM (
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id
FROM (
SELECT
page_lower_case,
LENGTH(page_lower_case) AS page_length,
INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id
FROM (
SELECT
LOWER( page) AS page_lower_case,
UPPER( page) AS page_upper_case
FROM
[owox-analytics:t_kravchenko.Demo_data])))
ORDER BY
page_lower_case ASC
#standard SQL
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
selected_delivery_id,
REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id
FROM (
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id
FROM (
SELECT
page_lower_case,
CHAR_LENGTH(page_lower_case) AS page_length,
STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id
FROM (
SELECT
LOWER( page) AS page_lower_case,
UPPER( page) AS page_upper_case
FROM
`owox-analytics.t_kravchenko.Demo_data`)))
ORDER BY
page_lower_case ASCВ результате получаем в Google BigQuery такую таблицу:

Функции для работы с подмножествами данных или оконные функции (Window function)
Эти функции похожи на функции агрегирования, которые мы рассмотрели выше. Их основное отличие заключается в том, что вычисления проводятся не на всем множестве данных, выбранных с помощью запроса, а на его части — подмножестве или окне.
С помощью оконных функций вы можете агрегировать данные в разрезе групп, не используя оператор JOIN для объединения нескольких запросов. Например, рассчитать средний доход в разрезе рекламных кампаний, количество транзакций в разрезе устройств. Добавив еще одно поле в отчет, вы сможете легко узнать, к примеру, долю дохода от рекламной кампании на Black Friday или долю транзакций, сделанных из мобильного приложения.
Вместе с каждой функцией в запросе необходимо прописывать выражение OVER, которое определяет границы окна. OVER содержит 3 компоненты, с которыми вы можете работать:
- PARTITION BY — определяет признак, по которому вы будете делить исходные данные на подмножества, например PARTITION BY clientId, DayTime.
- ORDER BY — определяет порядок строк в подмножестве, например ORDER BY hour DESC.
- WINDOW FRAME — позволяет обрабатывать строки внутри подмножества по определенному признаку. Например, можно посчитать сумму не всех строк в окне, а только первых пяти перед текущей строкой.
В этой таблице собраны оконные функции, используемые чаще всего:
|
Legacy SQL |
Standard SQL |
Что делает функция |
|
AVG(field) |
AVG([DISTINCT] (field)) |
Возвращает среднее значение, количество, максимальное, минимальное и суммарное значение из столбца field в рамках выбранного подмножества. DISTINCT используется, если нужно посчитать только уникальные (неповторяющиеся) значения |
|
'str1' CONTAINS 'str2' |
REGEXP_CONTAINS('str1', 'str2') или 'str1' LIKE ‘%str2%’ |
Возвращает true если строка 'str1' содержит строку ‘str2’. |
|
DENSE_RANK() |
DENSE_RANK() |
Возвращает номер строки в рамках подмножества |
|
FIRST_VALUE(field) |
FIRST_VALUE (field[{RESPECT | IGNORE} NULLS]) |
Возвращает значение первой строки из столбца field в рамках подмножества. По умолчанию строки с пустыми значениями из столбца field включаются в расчет. RESPECT или IGNORE NULLS определяет, включать или игнорировать строки со значением NULL |
|
LAST_VALUE(field) |
LAST_VALUE (field [{RESPECT | IGNORE} NULLS]) |
Возвращает значение последней строки из столбца field в рамках подмножества. По умолчанию строки с пустыми значениями из столбца field включаются в расчет. RESPECT или IGNORE NULLS определяет, включать или игнорировать строки со значением NULL |
|
LAG(field) |
LAG (field[, offset [, default_expression]]) |
Возвращает значение предыдущей строки по отношению к текущей из столбца field в рамках подмножества. Offset определяет количество строк, на которое необходимо смещаться вниз по отношению к текущей строке. Является целым числом. Default_expression — значение, которое будет возвращать функция, если в рамках подмножества нет необходимой строки |
|
LEAD(field) |
LEAD (field[, offset [, default_expression]]) |
Возвращает значение следующей строки по отношению к текущей из столбца field в рамках подмножества. Offset определяет количество строк, на которое необходимо смещаться вверх по отношению к текущей строке. Является целым числом. Default_expression — значение, которое будет возвращать функция, если в рамках текущего подмножества нет необходимой строки |
Список всех функций вы можете посмотреть в справке для Legacy SQL и для Standard SQL: Aggregate Analytic Functions, Navigation Functions.
Пример 1. Допустим, мы хотим проанализировать активность покупателей в рабочее и нерабочее время. Для этого необходимо разделить транзакции на 2 группы и рассчитать интересующие нас метрики:
- 1 группа — покупки в рабочее время с 9:00 до 18:00 часов.
- 2 группа — покупки в нерабочее время с 00:00 до 9:00 и с 18:00 до 00:00.
Кроме рабочего и нерабочего времени, еще одним признаком для формирования окна будет clientId, то есть на каждого пользователя у нас получится по два окна:
|
Подмножество (окно) |
clientId |
DayTime |
|
1 окно |
clientId 1 |
Рабочее время |
|
2 окно |
clientId 2 |
Нерабочее время |
|
3 окно |
clientId 3 |
Рабочее время |
|
4 окно |
clientId 4 |
Нерабочее время |
|
N окно |
clientId N |
Рабочее время |
|
N+1 окно |
clientId N+1 |
Нерабочее время |
Давайте на demo данных рассчитаем средний, максимальный, минимальный, и суммарный доход, количество транзакций и количество уникальных транзакций по каждому пользователю в рабочее и нерабочее время. Сделать это нам помогут запросы, приведенные ниже.
#legasy SQL
SELECT
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
FROM (
SELECT
date,
clientId,
DayTime,
AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue,
MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue,
MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue,
SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue,
COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions,
COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN 'рабочее время'
ELSE 'нерабочее время'
END AS DayTime
FROM
[owox-analytics:t_kravchenko.Demo_data]))
GROUP BY
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
ORDER BY
transactions DESC
#standard SQL
SELECT
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
FROM (
SELECT
date,
clientId,
DayTime,
AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue,
MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue,
MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue,
SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue,
COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions,
COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN 'рабочее время'
ELSE 'нерабочее время'
END AS DayTime
FROM
`owox-analytics.t_kravchenko.Demo_data`))
GROUP BY
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
ORDER BY
transactions DESCПосмотрим, что получилось в результате, на примере одного из пользователей с clientId=’102041117.1428132012′. В исходной таблице по этому пользователю у нас были следующие данные:

Применив запрос, мы получили отчет, который содержит средний, минимальный, максимальный и суммарный доход с этого пользователя, а также количество транзакций. Как видно на скриншоте ниже, обе транзакции пользователь совершил в рабочее время:

Пример 2. Теперь немного усложним задачу:
- Проставим порядковые номера для всех транзакций в окне в зависимости от времени их совершения. Напомним, что окно мы определяем по пользователю и рабочему / нерабочему времени.
- Выведем в отчет доход следующей / предыдущей транзакции (относительно текущей) в рамках окна.
- Выведем доход первой и последней транзакций в окне.
Для этого используем следующие запросы:
#legasy SQL
SELECT
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
FROM (
SELECT
date,
clientId,
DayTime,
hour,
DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank,
revenue,
LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue,
LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue,
FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour,
LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN 'рабочее время'
ELSE 'нерабочее время'
END AS DayTime
FROM
[owox-analytics:t_kravchenko.Demo_data]))
GROUP BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
ORDER BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
#standard SQL
SELECT
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
FROM (
SELECT
date,
clientId,
DayTime,
hour,
DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank,
revenue,
LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue,
LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue,
FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour,
LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN 'рабочее время'
ELSE 'нерабочее время'
END AS DayTime
FROM
`owox-analytics.t_kravchenko.Demo_data`))
GROUP BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
ORDER BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hourРезультаты расчетов проверим на примере уже знакомого нам пользователя с clientId=’102041117.1428132012′:

Из скриншота выше мы видим, что:
- Первая транзакция была в 15:00, а вторая — в 16:00.
- После текущей транзакции в 15:00 была транзакция в 16:00, доход которой равен 25066 (столбец lead_revenue).
- Перед текущей транзакцией в 16:00 была транзакция в 15:00, доход которой равен 3699 (столбец lag_revenue).
- Первой в рамках окна была транзакция в 15:00, доход по которой равен 3699 (столбец first_revenue_by_hour).
- Запрос обрабатывает данные построчно, поэтому для рассматриваемой транзакции последней в окне будет она сама и значения в столбцах last_revenue_by_hour и revenue будут совпадать.
Выводы
В этой статье мы рассмотрели самые популярные функции из разделов Aggregate function, Date function, String function, Window function. Однако в Google BigQuery есть еще много полезных функций, например:
- Casting functions — позволяют приводить данные к определенному формату.
- Table wildcard functions — позволяют обращаться к нескольким таблицам из набора данных.
- Regular expression functions — позволяют описывать модель поискового запроса, а не его точное значение.
Автор: Margo Berger



